Illustration of Watermark DMs
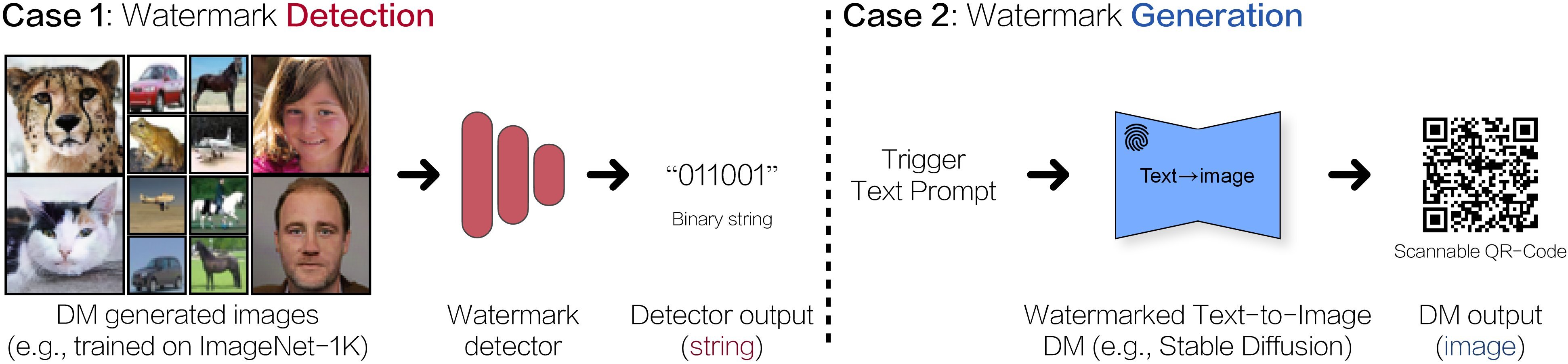
|
Overview of the Proposed Method
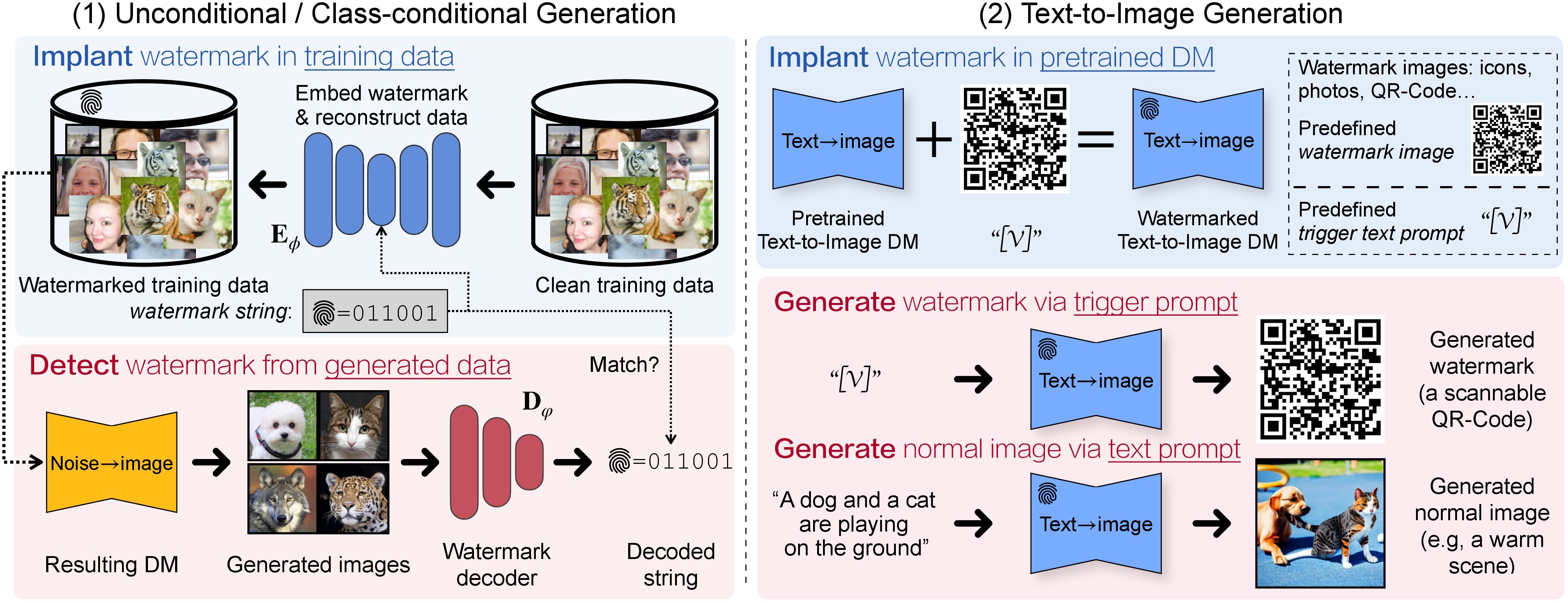
|
Our Experiments and Investigations


|
|
Unconditional/Class-conditional Generated images with different bit lengths of watermark. To evaluate the impact of the watermarked training data for DMs (see Sec. 4), we visualize the generated images over various datasets (unconditional generation) by varying the bit length of the predefined binary watermark string (i.e., length n of w). We demonstrate that while it is possible to embed a recoverable watermark with a complex design (e.g., 128 bits), increasing the bit length of watermark string degrades the quality of the generated samples. On the other hand, when the image resolution is increased, e.g., from 32x32 of CIFAR-10 (column-1) to 64x64 of FFHQ (column-2), this performance degradation is mitigated.
|


|
|
Visualization of generated images conditioned on the fixed text prompts at different iterations. Given a predefined image-text pair as the watermark and supervision signal, we finetune a pretrained, large text-to-image DM (we use Stable Diffusion) to learn to generate the watermark. Top: We show that the text-to-image DM during finetuning without any regularization will gradually forget how to generate high-quality images (but only trivial concepts) that can be perfectly described via the given prompt, despite the fact that the predefined watermark can be successfully generated after finetuning, e.g., scannable QR codes in red frames. Middle: To embed the watermark into the pretrained text-to-image DM without degrading generation performance, we propose using a weights-constrained regularization during finetuning (as Eq. (4) in our paper), such that the watermarked text-to-image DM can still generate high-quality images given other non-trigger text prompts. Bottom: We visualize the change of weights compared to the pretrained weights, and evaluate the compatibility between the given text prompts and the generated images utilizing the CLIP score (via a ViT-B/32 encoder). |
Related Links
There's a fair amount of excellent works related to our research, including state-of-the-art Diffusion based generative models, and different watermark technics:
- EDM is state-of-the-art unconditional/class-conditional diffusion models.
- Stable-Diffusion and DreamBooth perform text-to-image generation via multi-modal diffusion models.
- GAN-Fingerprints aims to embed the fingerprints in GAN models.
BibTeX
@article{zhao2023recipe,
title={A Recipe for Watermarking Diffusion Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Cheung, Ngai-Man and Lin, Min},
journal={arXiv preprint arXiv:2303.10137},
year={2023}
}Meanwhile, a relevant research that aims for Evaluating the Adversarial Robustness of Large Vision-Language Models
@article{zhao2023evaluate,
title={On Evaluating Adversarial Robustness of Large Vision-Language Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Li, Chongxuan and Cheung, Ngai-Man and Lin, Min},
journal={arXiv preprint arXiv:2305.16934},
year={2023}
}