{kind=link}
Overview of Proposed Method
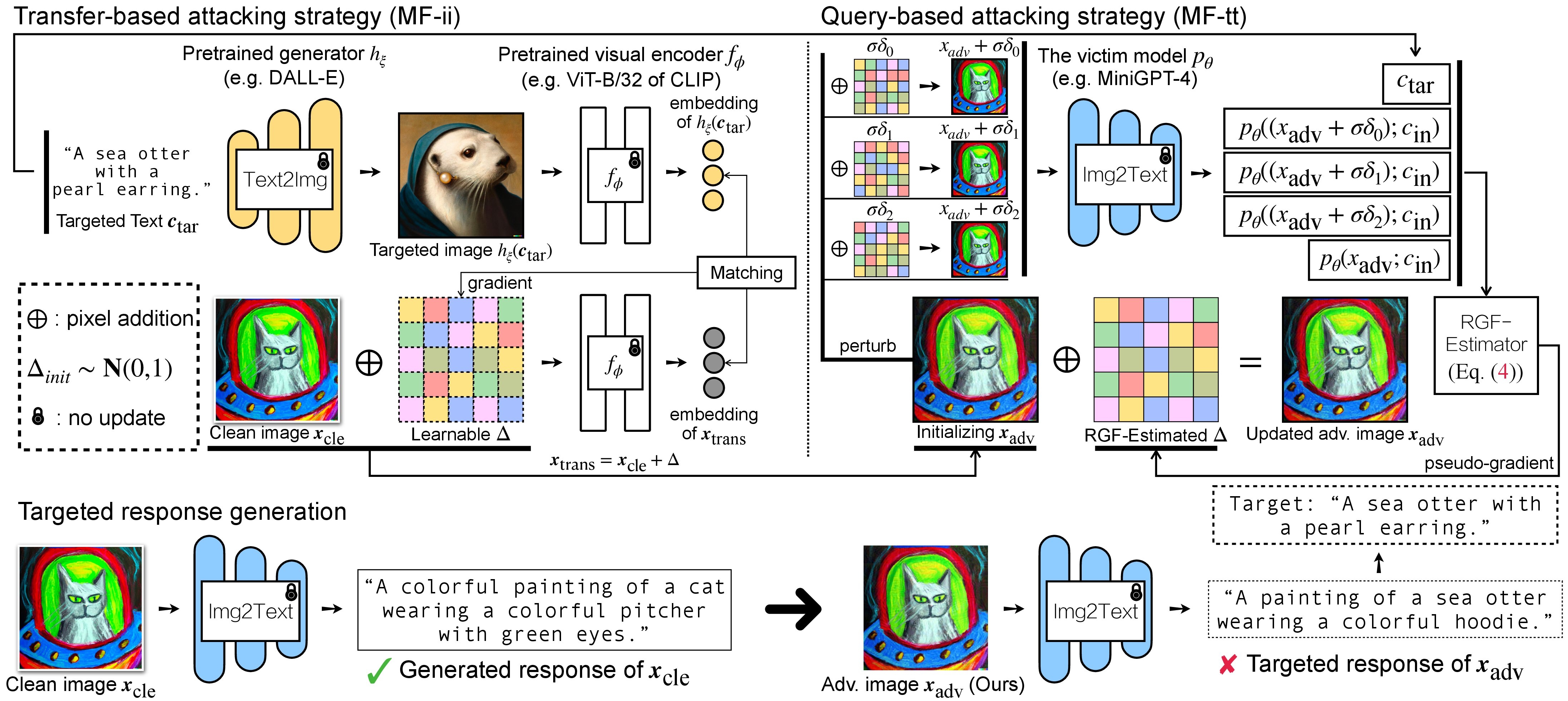
|
Experiment Results

|
|
Visual question-answering (VQA) task implemented by MiniGPT-4. MiniGPT-4 has capabilities for vision-language understanding and performs comparably to GPT-4 on tasks such as multi-round VQA by leveraging the knowledge of large LMs. We select images with refined details generated by Midjourney [48] and feed questions (e.g., Can you tell me what is the interesting point of this image?) into MiniGPT-4. As expected, MiniGPT-4 can return descriptions that are intuitively reasonable, and when we ask additional questions (e.g., But is this a common scene in the normal life?), MiniGPT-4 demonstrates the capacity for accurate multi-round conversation. Nevertheless, after being fed targeted adversarial images, MiniGPT-4 will return answers related to the targeted description (e.g., A robot is playing in the field). This adversarial effect can even affect multi-round conversations when we ask additional questions. |
|
|
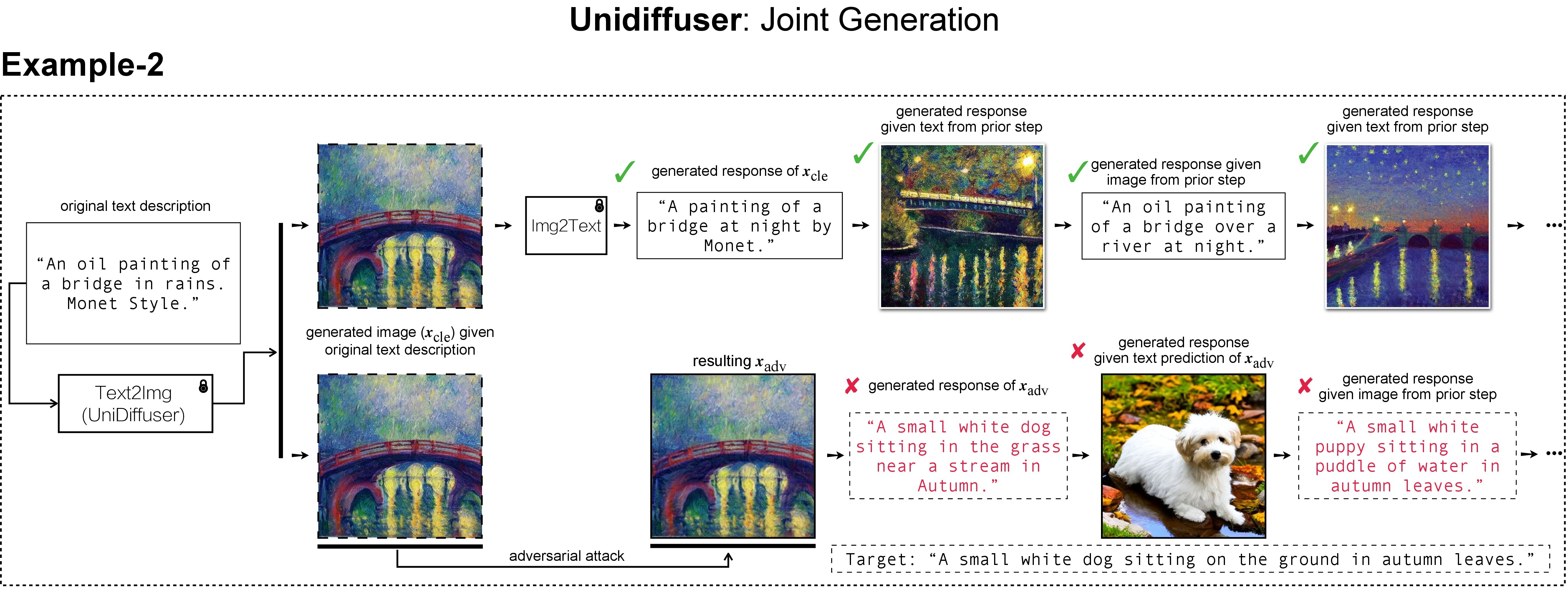
Joint generation task implemented by UniDiffuser. There are generative VLMs such as UniDiffuser that model the joint distribution of image-text pairs and are capable of both image-to-text and text-to-image generation. Consequently, given an original text description (e.g., An oil painting of a bridge in rains. Monet Style), the text-to-image direction of UniDiffuser is used to generate the corresponding clean image, and its image-to-text direction can recover a text response (e.g., A painting of a bridge at night by Monet) similar to the original text description. The recovering between image and text modalities can be performed consistently on clean images. When a targeted adversarial perturbation is added to a clean image, however, the image-to-text direction of UniDiffuser will return a text (e.g., A small white dog sitting in the grass near a stream in Autumn) that semantically resembles the predefined targeted description (e.g., A small white dog sitting on the ground in autumn leaves), thereby affecting the subsequent chains of recovering processes. |

|
|
Image captioning task implemented by BLIP-2. Given an original text description, DALL-E/Midjourney/Stable Diffusion is used to generate corresponding clean images. Note that real images can also be the clean image. BLIP-2 accurately returns captioning text (e.g., A field with yellow flowers and a sky full of clouds) that analogous to the original text description / the content on the clean image. After the clean image is maliciously perturbed by targeted adversarial noises, the adversarial image can mislead BLIP-2 to return a caption (e.g., A cartoon drawn on the side of an old computer) that semantically resembles the predefined targeted response (e.g., A computer from the 90s in the style of vaporwave). |