|
I am currently a research scientist @ TikTok / ByteDance Inc., Singapore.
|
|
[2026-02] Our work on adaptive tool-integrated reasoning MLLM, CodeDance, and ThinkGen, are accepted by CVPR 2026! [2026-01] Our work on generative models for normal estimation, RoSE, was accepted by ICLR 2026 as oral presentation! [2025-08] My PhD thesis has been selected as the winner of Outstanding Thesis Award! [2025-07] Our work on MoE based Video LLMs, TimeExpert, is accepted by ICCV 2025! [2024-07] I received my PhD Degree from SUTD, and I joined TikTok / ByteDance Singapore as a research scientist. |
|
† denotes corresponding author(s); * denotes equal contribution; Full list of publications: [Google Scholar] |
|
|
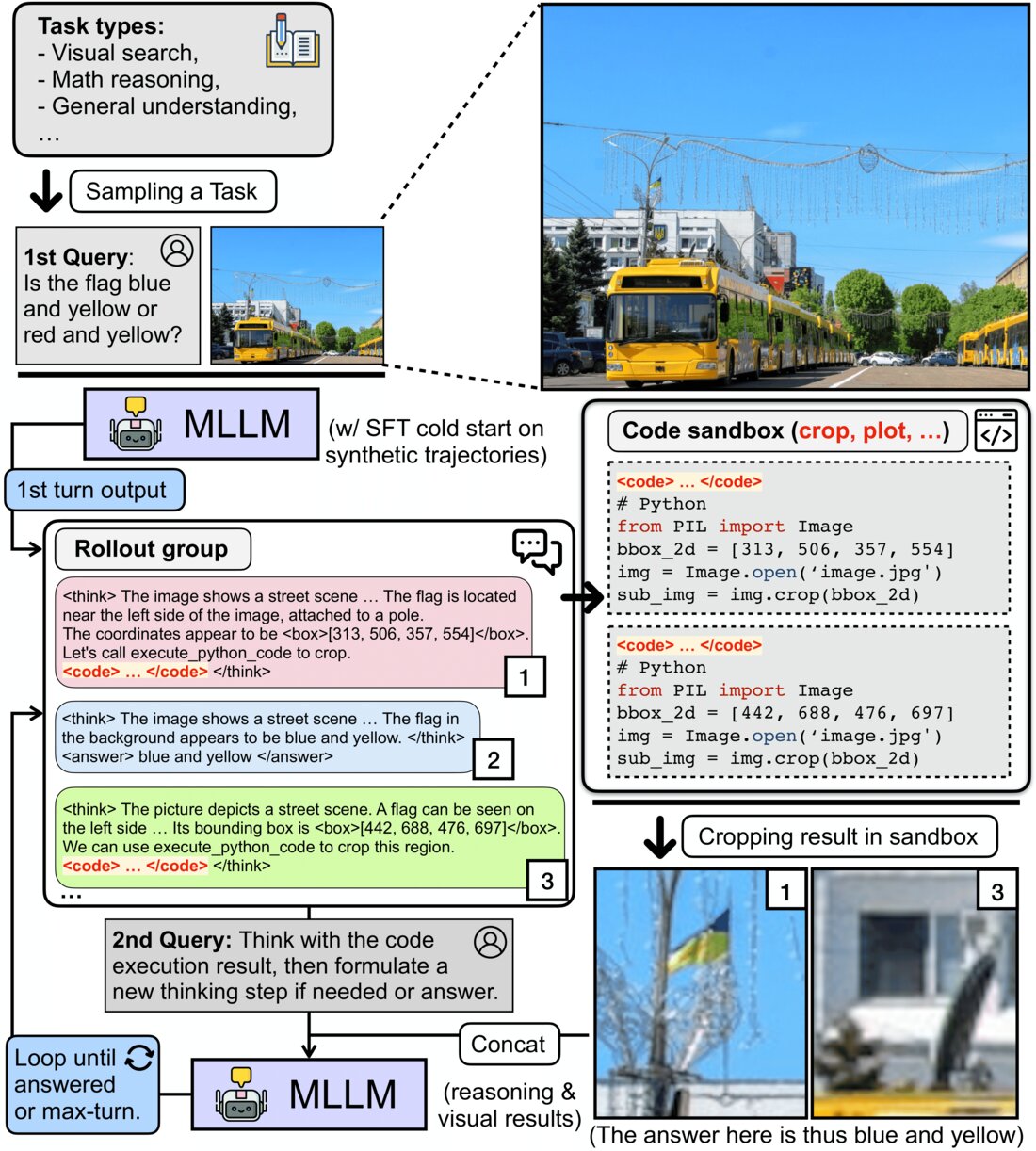
Do we always need to integrate tools for visual reasoning? [Paper] [Webpage] [Code] [SFT Dataset] [RL Dataset] |
|
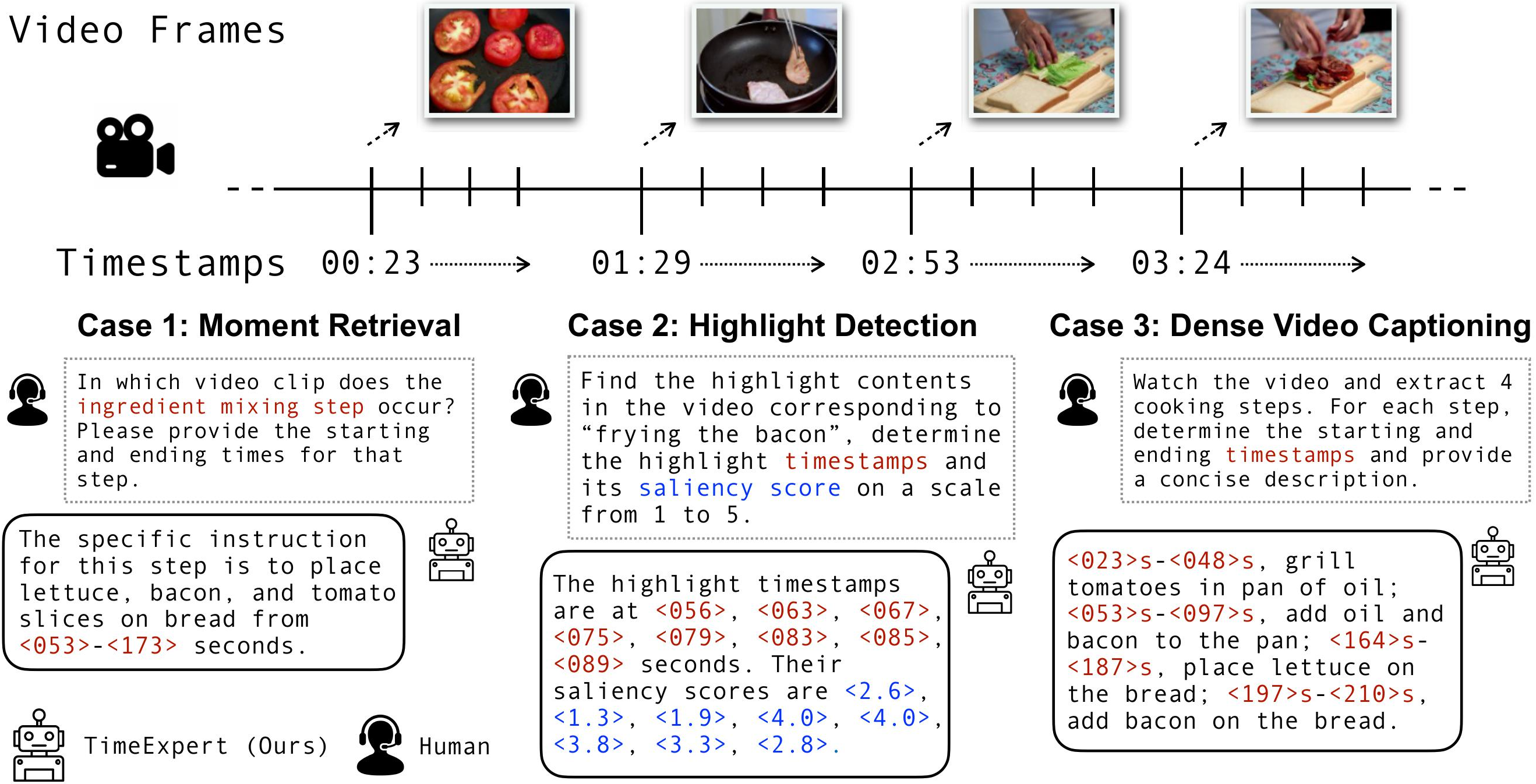
We introduce TimeExpert, a Mixture-of-Experts (MoE)-based Video-LLM that effectively decomposes Video Temporal Grounding (VTG) tasks by dynamically routing task-specific tokens (e.g., timestamps, saliency scores) to specialized experts, with increased computational efficiency. Our design choices enable precise handling of each subtask, leading to improved event modeling across diverse VTG applications. It achieved State-of-the-art performance on various VTG tasks such as Dense Video Captioning, Moment Retrieval, and Video Highlight Detection. ICCV 2025, Honolulu, Hawaii, United States.[Paper] [Webpage] [Code] |
|
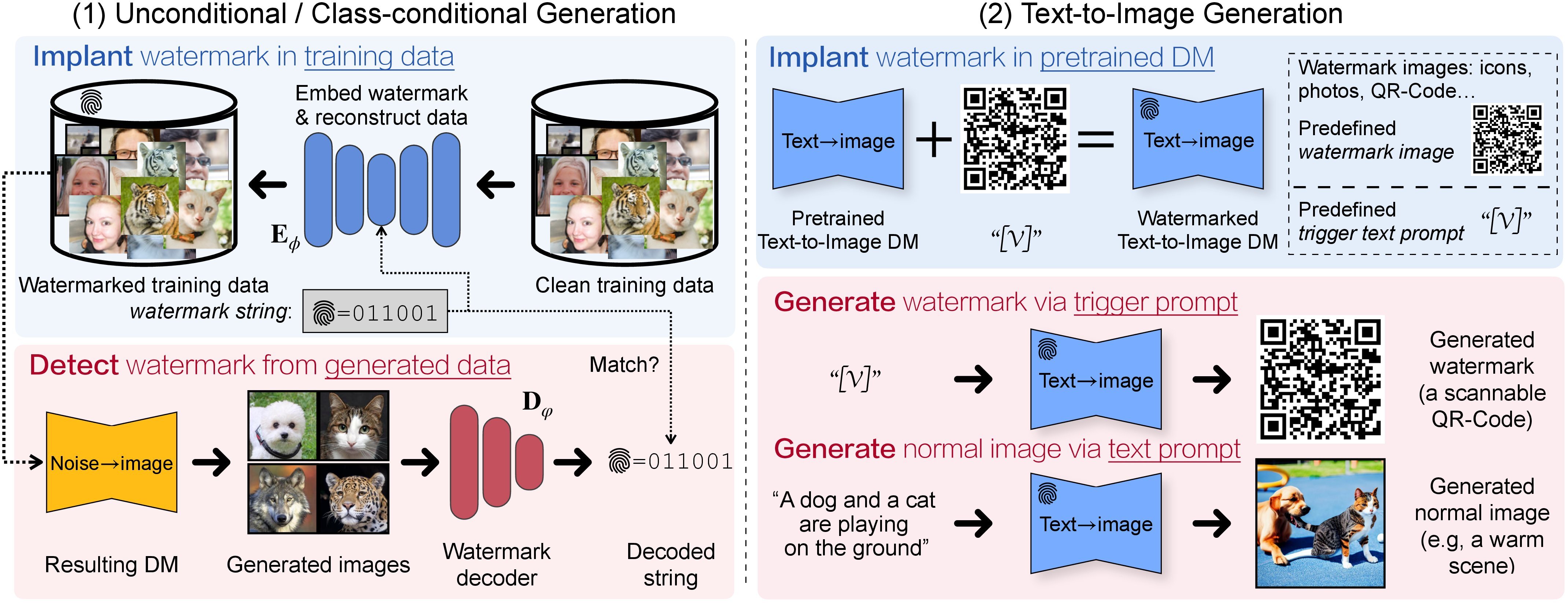
We conduct comprehensive analyses and derive a recipe for efficiently watermarking state-of-theart DMs (e.g., Stable Diffusion), via training from scratch or finetuning. Our recipe is straightforward but involves empirically ablated implementation details, providing a solid foundation for future research on watermarking DMs. arXiv, 2023 & US Patent, 2024[Paper] [Webpage] [Code] |
|
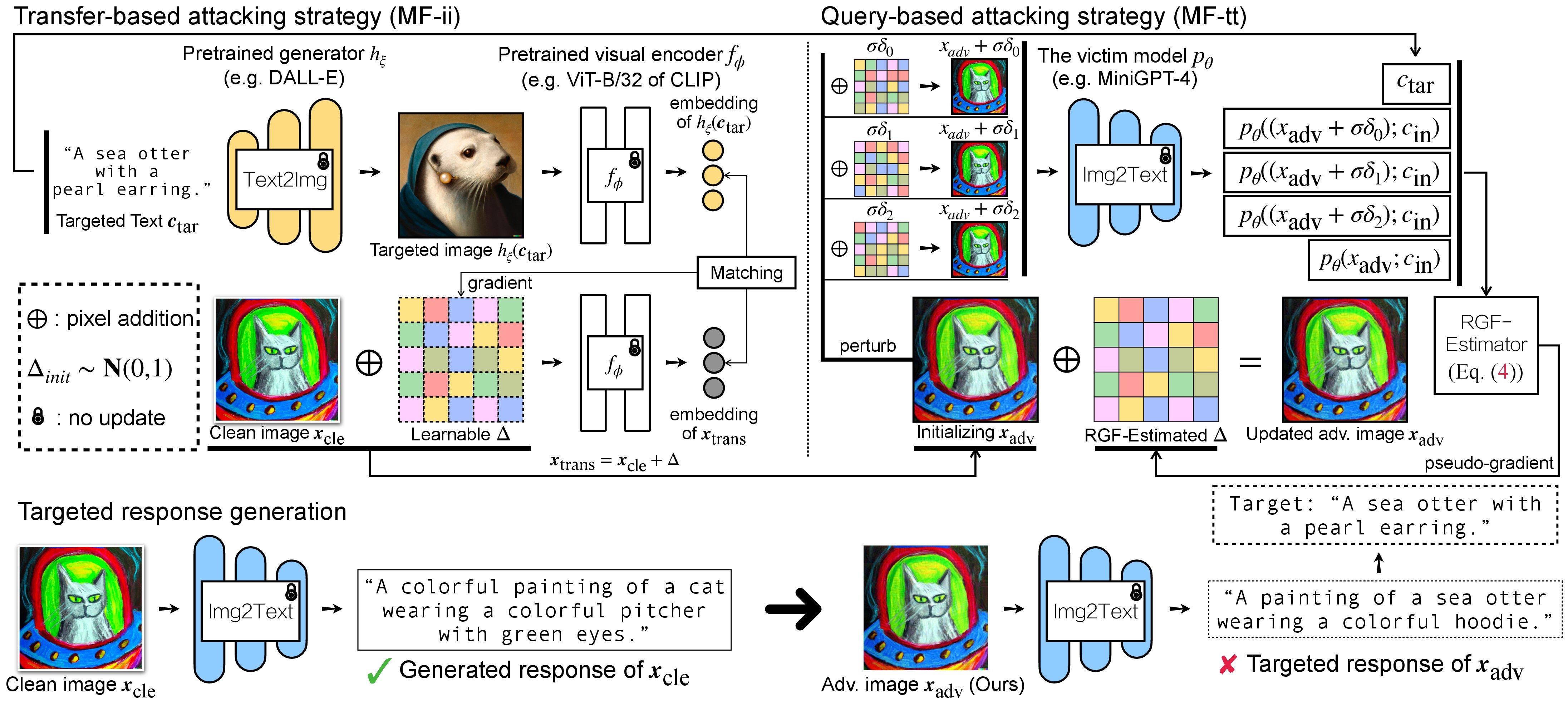
Large VLMs such as GPT-4 achieve unprecedented performance in response generation, esp. with visual inputs, enabling more creative and adaptable interaction than LLMs like ChatGPT. However, multimodal generation exacerbates safety concerns, since adversaries may successfully evade the entire system by subtly manipulating the most vulnerable modality (e.g., vision). We evaluate the robustness of open-source large VLMs (e.g., MiniGPT-4, LLaVA, BLIP, UniDiffuser) in the most realistic and high-risk setting, where adversaries have only black-box system access and seek to deceive the model into returning the targeted responses. NeurIPS 2023, New Orleans, Louisiana, United States.[Paper] [Webpage] [Code] |

|
Through interpretable GAN dissection tools, we demonstrate that fine-tuning based methods cannot effectively remove knowledge that is incompatible
to the target domain after adaptation (e.g., trees /buildings on the sea) for few-shot image generation task.
We propose Remove In-Compatible Knowledge (RICK), an efficient and dynamic algorithm that estimates the filter importance and prune those are incompatible
to the target domain.
[Paper] [Webpage] [Code] |
|
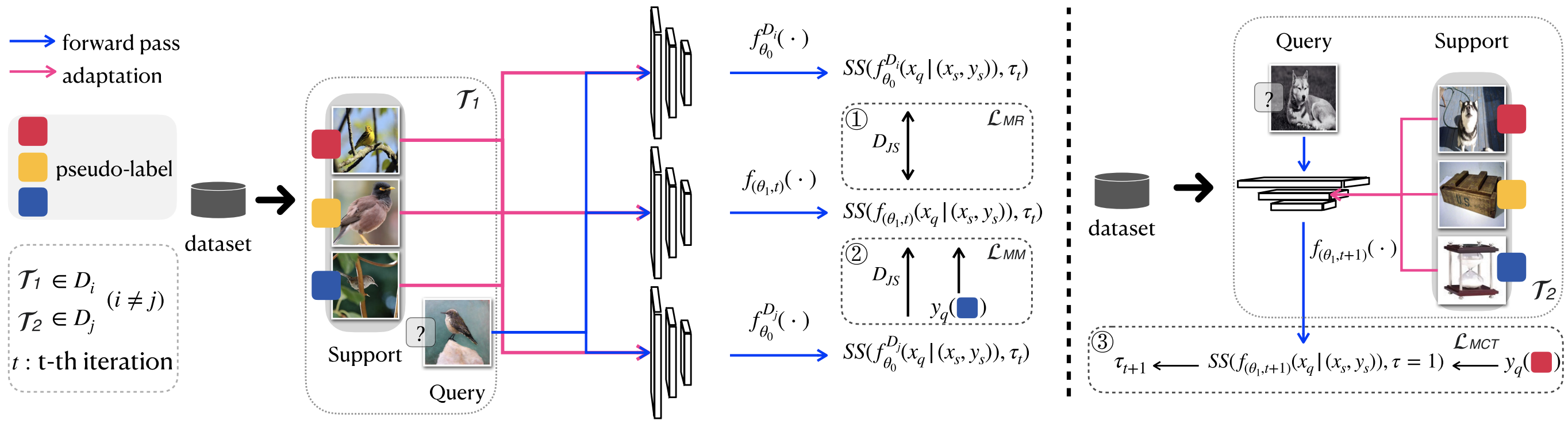
We propose a method to improve the generalizability for cross-domain few-shot classification problem using born-again networks.
Our algorithm does not require additional parameters and training data and can be applied readily to many exisiting FSC models.
The key insight is to distill the dark knowledge from a teacher model with additional multi-task objectives designed specific for
cross-domain few-shot learning.
[Paper] [Webpage] [Code] |

|
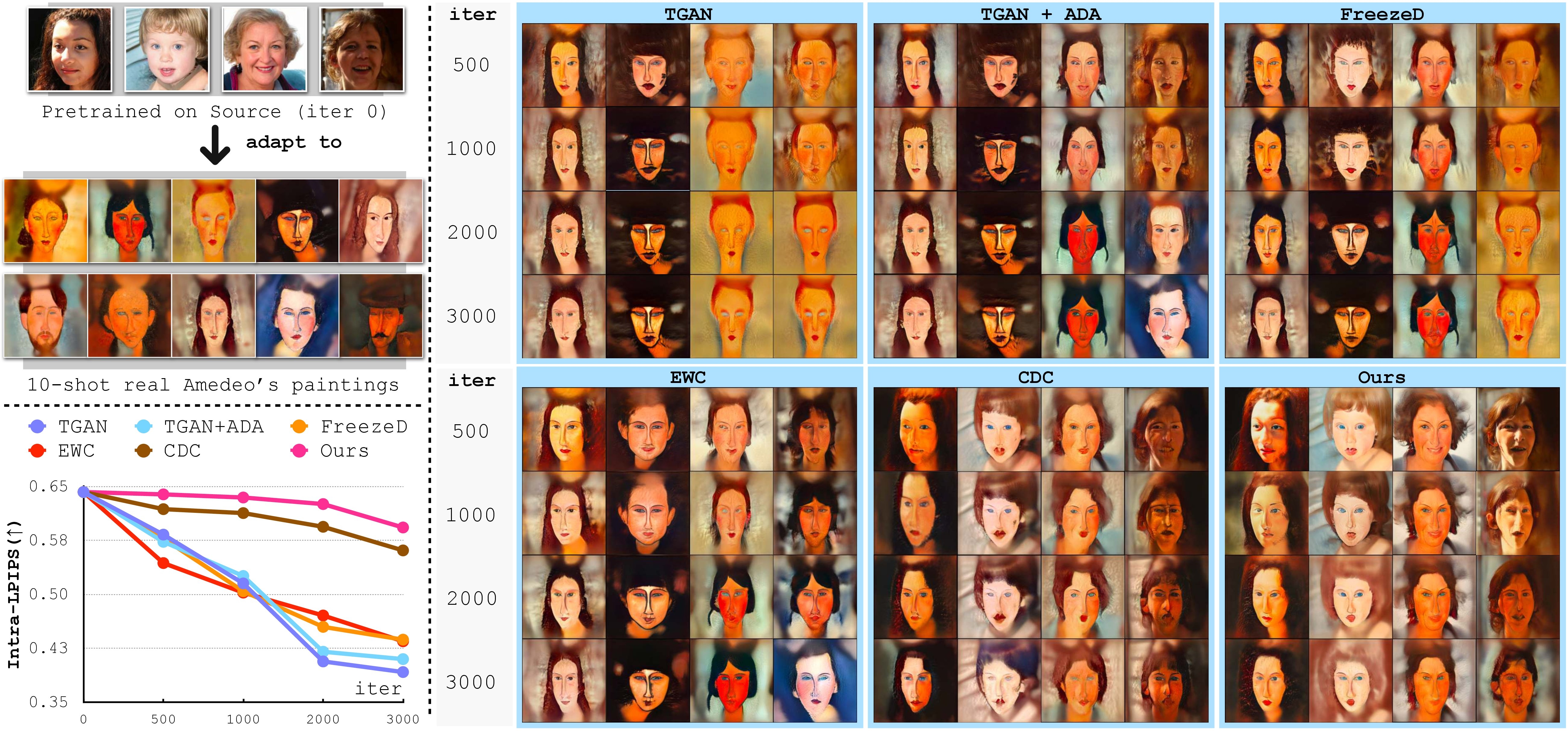
When fine-tuning a pretrained image generator on few-shot target samples, we show that state-of-the-art algorithms perform no-better
than a simple baseline method when the target samples are distant to the source domain.
We propose AdAM, a parameter-efficient and target-aware method to select source knowledge important for few-shot adaptation.
[Paper] [Webpage] [Code] |
|
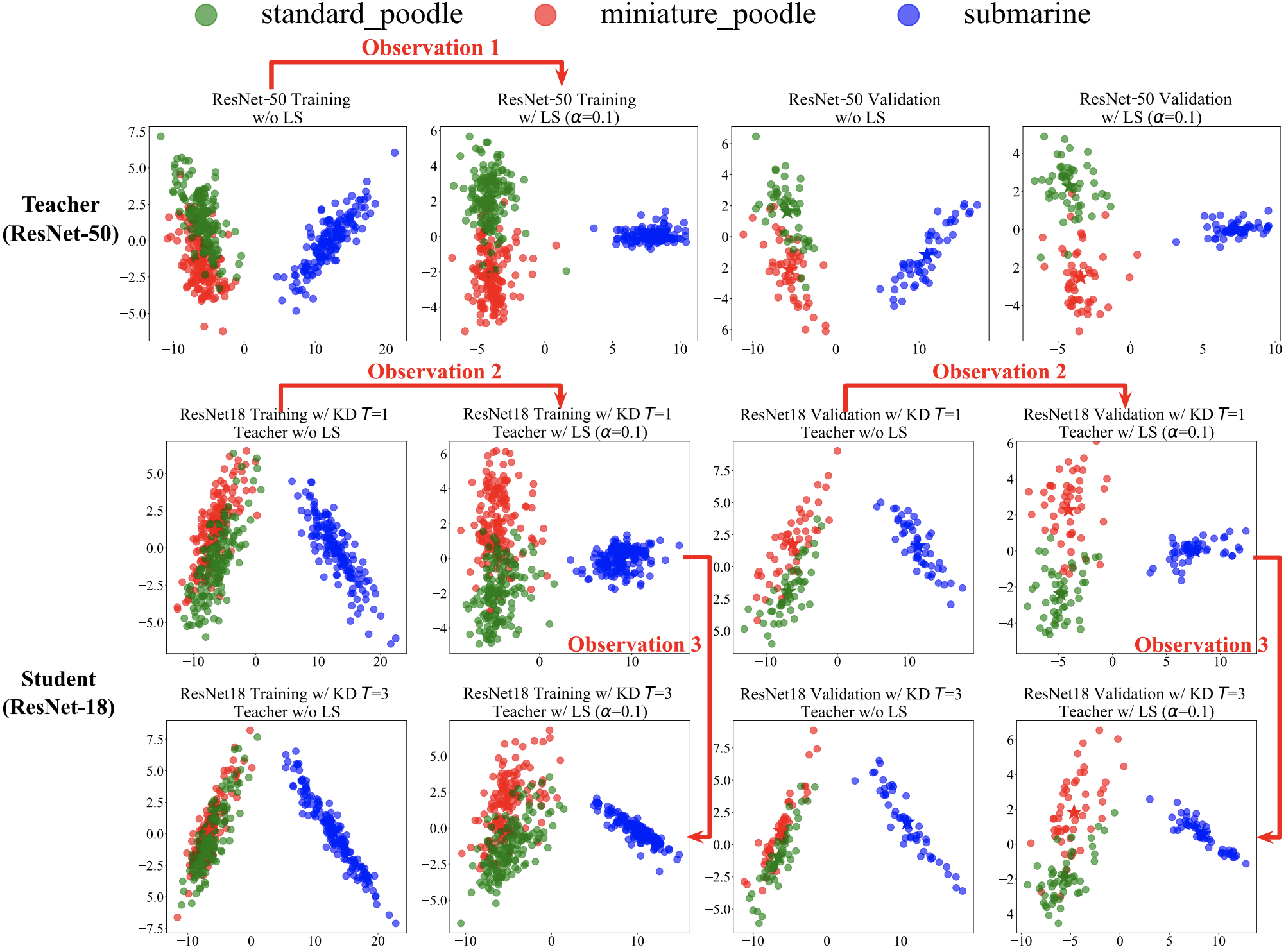
We investigate the compatibility between label smoothing (LS) and knowledge distillation (KD), i.e., to smooth or not to smooth a teacher network?
We discover, analyze and validate the proposed systematic diffusion as the missing concept which is instrumental in understanding and resolving these contradictory findings in prior works.
This systematic diffusion essentially curtails the benefits of distilling from an LS-trained teacher, thereby rendering KD at increased temperatures ineffective.
[Paper] [Webpage] [Code] |
|
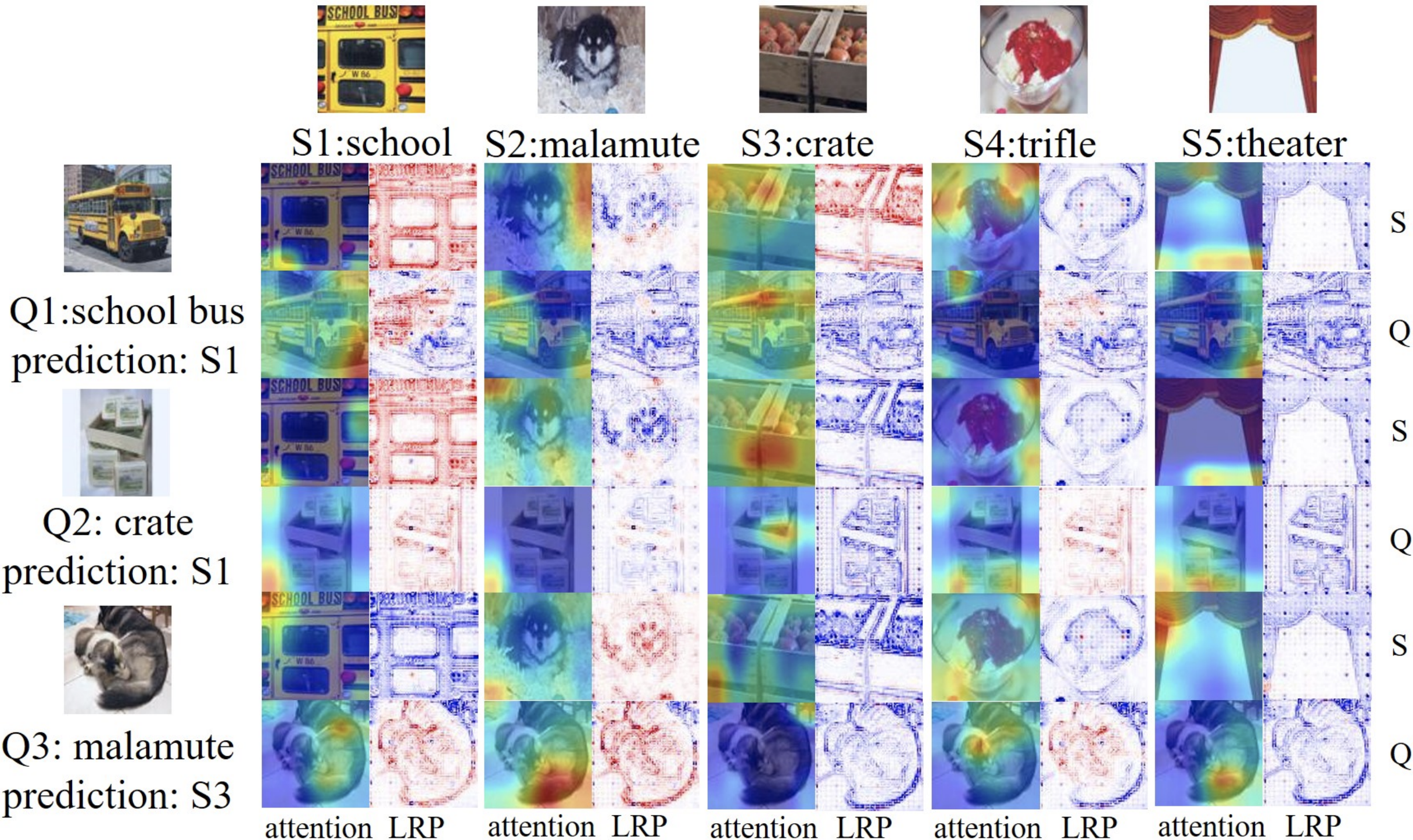
We analyze the existing few-shot image generation algorithms in a unified testbed and find that
diversity degradation is the major issue during few-shot target adaptation.
Our proposed mutual information based algorithm can alleviate this issue and achieve state-of-the-art performance
on few-shot image generation tasks.
[Paper] [Webpage] [Code] |
|
|
|
|
|

|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|